
In today’s data-driven world, organizations increasingly adopt data lakes as a strategic approach to manage vast amounts of data from diverse sources. Data lakes offer scalability, flexibility, and the capacity to extract insights from both organized and unstructured data. Creating and maintaining a successful date lake presents its own set of difficulties. This article explores the intricacies and factors that builders must consider while constructing data lakes, examining the challenges that businesses face and the most effective ways to overcome them. Data lakes, as opposed to typical data warehouses, can store structured, semi-structured, and unstructured data from a wide range of sources, such as databases, IoT devices, apps, and more.
The Main Challenges with Data Lakes
Data lakes provide advantages, but to fully utilize them, organizations need to overcome several obstacles:
Data Governance: The volume and variety of data can make it challenging for organizations to maintain data security, compliance, and quality within a data lake ecosystem. Organizations must implement strong governance systems to ensure regulatory compliance and integrity.
Data Quality: Ensuring the quality of data is essential. Inconsistent or incomplete raw data that organizations ingest into data lakes may impact decision-making and downstream analytics.
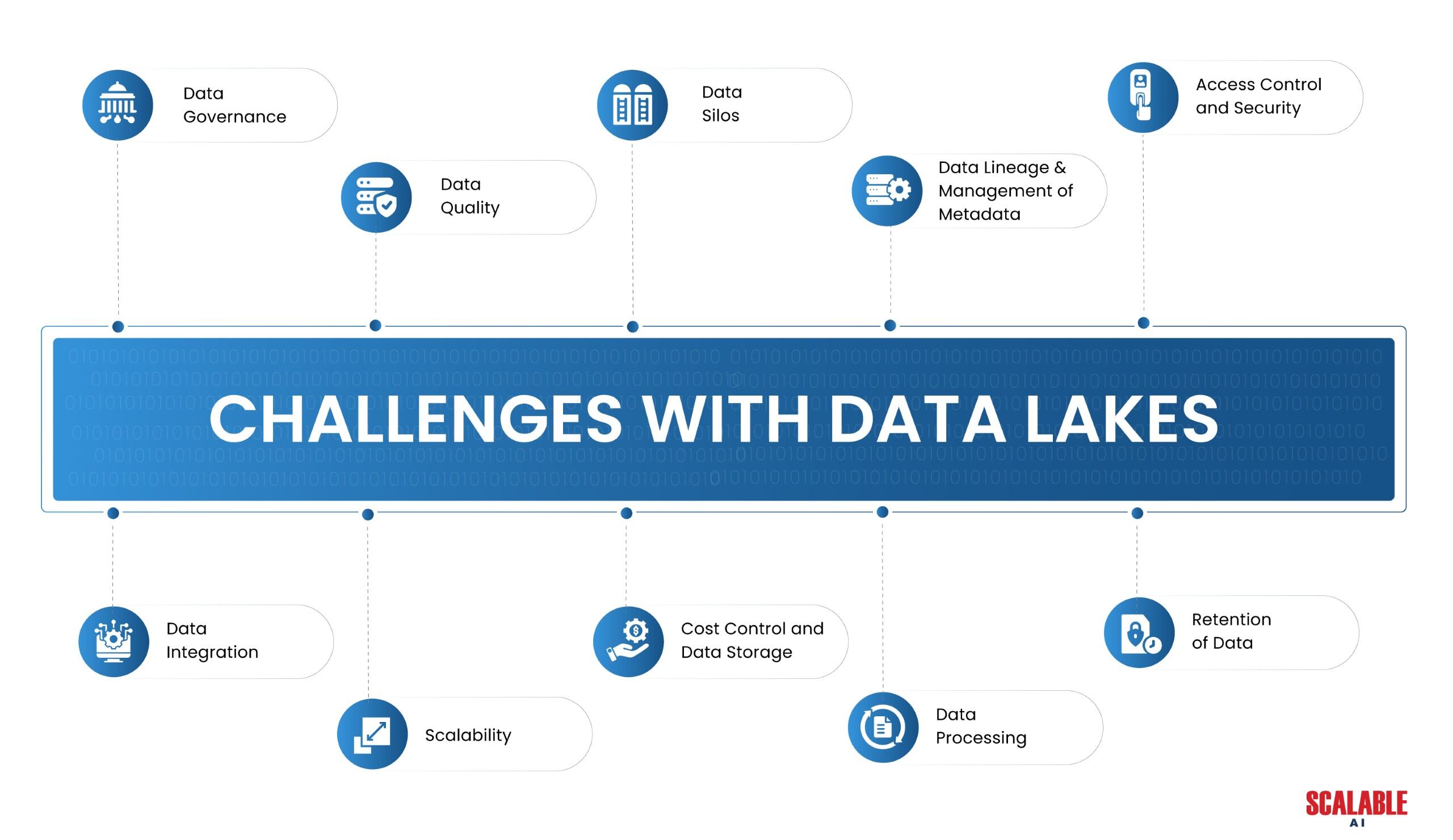
Data Silos: If improperly managed, data lakes can unintentionally become data swamps, which leads to an increase in data due to separation of datasets and the restriction of data accessibility.
Data Lineage and Management of Metadata: Understanding data origins, transformations, and usage – which can be difficult at scale – requires managing metadata and tracking data lineage.
Access Control and Security: Safeguarding sensitive data requires that we ensure appropriate access controls and protect data lakes from unwanted access.
Data Integration: Planning and carrying out the integration of data from various sources into a coherent framework with care is necessary.
Scalability: Scalable infrastructure and effective data processing capabilities are necessary to manage the scalability of data lakes as data quantities increase.
Cost Control and Data Storage: Large-scale data storage can be expensive, so data life cycle management and cost-effective storage options are required.
Data Processing: Optimized data pipelines and processing frameworks are necessary to analyze huge datasets for analytics and insights promptly.
Retention of Data: Managing the data lifecycle and complying with regulations requires the establishment of policies for data archiving and preservation.
Overcoming Data Lake Challenges: Optimal Methods and Approaches
Effectively managing a data lake requires handling the many challenges that arise from processing vast amounts of heterogeneous data. The following are essential tactics and recommended procedures for addressing typical issues related to data lakes:
Framework for Data Governance:
Establish a strong framework for data management and governance that consists of:
Data Quality Management: To guarantee high-quality data, establish data quality standards, conduct frequent audits, and implement data cleansing procedures.
Security and Access Controls: Implement encryption, enforce role-based access rules, and monitor activities to safeguard confidential information and ensure compliance with legal obligations.
MetaData Management: To trace data provenance, history, and consumption throughout the data lake ecosystem, and establish metadata standards and tools.
Assurance of Data Quality
- To find and fix data abnormalities and inconsistencies, automate data quality checks and validation procedures at the points of data ingestion.
- Utilize data profiling tools to examine patterns in data and spot possible problems with quality at the very beginning of the data lifecycle.
Data Lake Architecture and Design
- Use a flexible and scalable architecture that can handle streaming and batch data processing.
- Implement encryption, establish role-based access rules, and monitor systems to safeguard confidential information and ensure compliance with legal obligations.
Pipeline Management and Data Integration
- Construct strong pipelines for data integration so that data from many sources can be loaded, transformed, and ingested into the data lake.
- Use workflow and data orchestration tools to automate data input, transformation, and processing operations
Scalability and Performance
- To handle expanding data volumes and processing requirements, use cloud-based data lake solutions that provide elastic scalability and on-demand resources.
- For better speed, optimize data lake processing and storage utilizing cloud-native services or distributed computing frameworks like Apache Spark.
Cost Optimization
- To optimize storage costs, implement data lifecycle management strategies to tier data storage based on retention needs and access frequency.
- Use pay-as-you-go and serverless cloud services to process and analyze data more affordably.
Privacy and Data Security
- Put in place thorough data security procedures, such as data masking, safe authentication methods, and encryption both in transit and at rest.
- To identify and reduce security risks and unauthorized access, audit and monitor data usage and access regularly.
Cooperation and Democratization of Data
- By giving individuals within the company access to self-service analytics tools and data exploration capabilities, you may encourage a collaborative and data-democratization culture.
- To encourage data ownership and accountability, define roles and responsibilities for data stewardship.
Constant Observation and Improvement
- Establish logging and monitoring systems to keep tabs on data quality metrics, consumption trends, and data lake performance.
- Optimize data lake workflows and infrastructure continuously using analytics and monitoring insights.
Training and Skill Development
- To upskill data engineers, data scientists, and analysts on data lake technologies, best practices, and new trends, invest in training programs.
- Encourage a culture that is driven by data that highlights the significance of analytics, governance, and high-quality data for well-informed decision-making.
Conclusion
Organizations may overcome the inherent difficulties posed by data lakes and fully utilize their data assets to spur innovation and corporate growth by using these best practices and tactics.
Read Whitepaper Data Lake Navigation: Unraveling Insights in the Sea of Information