
Data is one of the most significant assets for businesses in the modern digital landscape. Effective management, storing, and analysis of data can be time-consuming due to its vast quantity and diversity. In this situation, a data lake is useful. This comprehensive manual will walk you through the whole process of creating a data lake, from design and setup to execution.
Organizing a Data Lake
Determine the Goals and Purpose of Your Data Lake: It will be easier to match the design of your data lake with your corporate objectives if you take the time to determine your business aim. Let’s say you run a retail business and want to improve the way you handle your inventory. The manufacturing company that plans to store data from supply chain logistics for predictive maintenance will not have the same data lake structure as you.
Choose the Data Types You Wish to Store: The data you wish to collect will greatly impact your planning process. Thus, your preference for semi-structured data—such as social media interactions—or unstructured data, such as customer reviews and sales transactions, plays a crucial role. The kind of data your company maintains will determine how you design your data lake.
Select the Right Architecture and Technology for Your Data Lake: Technically speaking, cloud-based solutions such as Amazon S3 are affordable and scalable. Other than that, the data lake offers further AWS-compatible options for data processing and analysis. In terms of architecture, companies seeking a single perspective of their data might find success with a centralized approach.
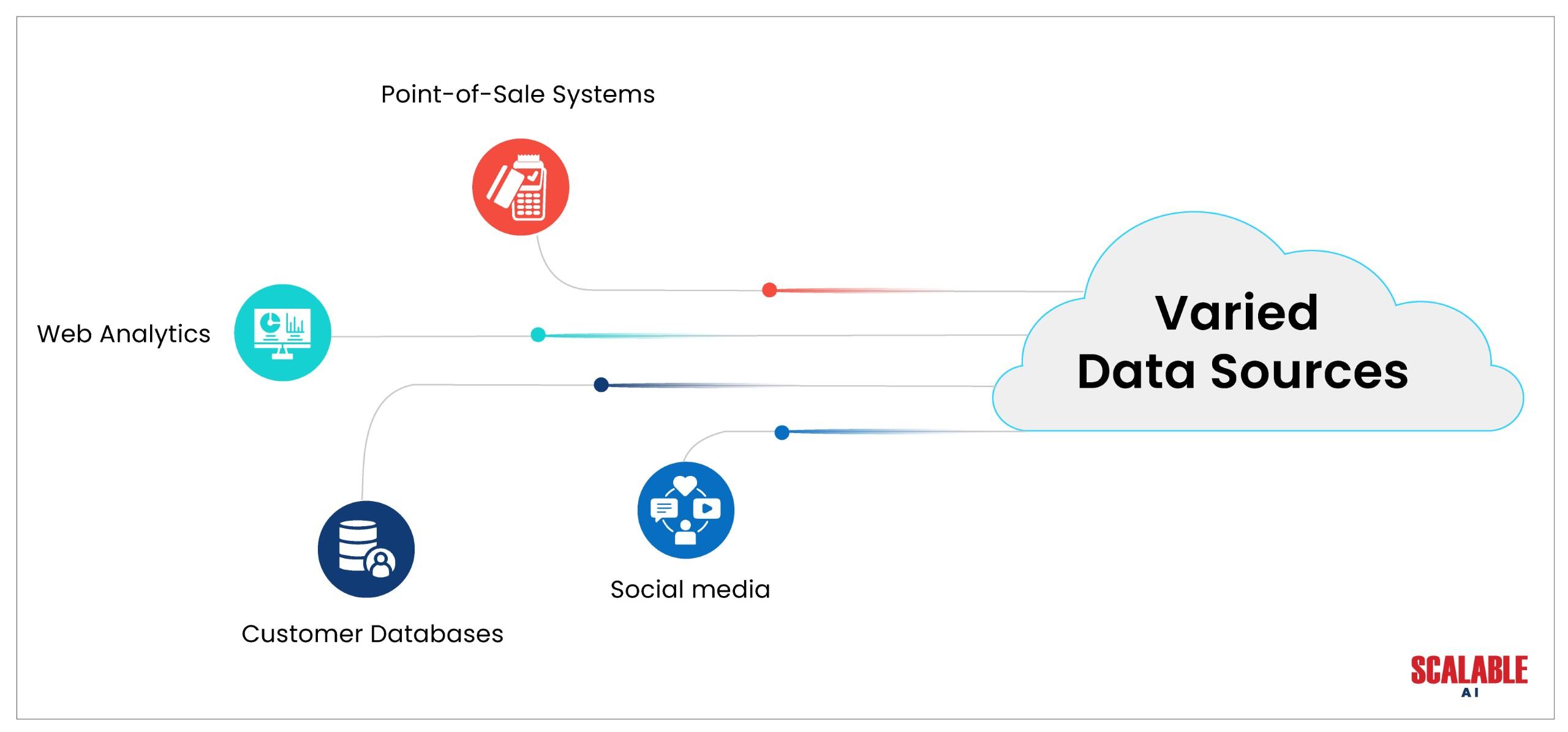
Setting Up Data for Your Lake
Gathering and Combining Information from Different Sources: Preparing data for a data lake is the next step after planning one. Businesses need to collect data from several sources, including social media platforms, website analytics, and customer databases, to prepare the data. If your business is retail, you might obtain sales information from online transactions, point-of-sale systems, or client feedback.
Data Cleaning and Filtering to Ensure Consistency and Accuracy: Data cleansing and filtering are crucial since proper and consistent information is a need for any firm. Errors must be fixed, duplicates must be eliminated, and formats must be standardized. For instance, a healthcare organization can edit patient records to remove typographical and formatting errors.
Organizing Data to Make It Easy to Access and Analyze: The enormous amount of data kept in the data lake must be organized and understood using data schemas and metadata. While metadata offers descriptive information about the data, proper schemas can organize and classify the data to facilitate effective querying and analysis. Automated metadata management and schema building are possible with services like AWS Glue.
Filling Up Your Data Lake
Adding Data to Your Lake using several Techniques: A data lake specialist will fill your data lake through data ingestion. They use several techniques in the process, including streaming, batch processing, and real-time data pipelines. You can leverage AWS services such as AWS Data Pipeline for automated workflows, Amazon Kinesis for streaming data, and AWS Glue for batch ingestion.
Tracking and Improving Data Ingestion Efficiency: Constructing a data lake on AWS demands that you carefully monitor and optimize data input performance. By monitoring during the lake-building process, you can promptly detect obstructions and inefficiencies, which will help maximize the utilization of AWS cloud storage. If you neglect this step, it might result in storage data silos, increased expenses, and diminished performance, ultimately decreasing the efficacy of analytics and data lake projects.
Maintaining Access Control and Data Security: When businesses add data to a data lake, they need to protect sensitive information and comply with regulations. Neglecting security could lead to breaches, compromised data integrity, and legal ramifications. To help prevent unauthorized access and data breaches, AWS provides sophisticated access restrictions and encryption methods.
Data Analysis of Your Lake
Getting Knowledge from Your Data with Analytics and Visualization Tools: You can extract actionable insights from a data lake by using analytics and visualization technologies like Amazon QuickSight and Amazon Redshift. These technologies allow businesses to examine data, spot trends, and make wise judgments. Visualizations enhance understanding by presenting data in a comprehensible style.
Utilizing AI and Other Cutting-Edge Methods with Your Data: The most popular way to guarantee accurate analysis and improve predictive capabilities in a data lake is to use machine learning methodologies and other cutting-edge techniques. Amazon SageMaker simplifies the integration of machine learning models into data analysis workflows, which enables businesses to obtain deeper insights and make more informed decisions.
Communicating and Sharing Your Results with Stakeholders: Businesses can align their processes with organizational objectives by exchanging findings. An online retailer can utilize data from the data lake to provide insights into consumer buying habits, aiding in product development and marketing strategies. This transparency ensures that interested parties understand the reasoning behind decisions.
Conclusion
To sum up, businesses can fully utilize the power of their data by creating a data lake. With the help of this comprehensive handbook, companies can establish a solid basis for innovation and make data-driven decisions. Data lakes become strategic assets that spur innovation and expansion, thanks to their smooth connection with AWS services and their sophisticated analytics and visualization capabilities.
Read Whitepaper Data Lake Navigation: Unraveling Insights in the Sea of Information